
Sit down in your chair and relax. Close your eyes and think about a system that you wouldn’t like to work on. What would it be like? Let’s check how much in common it would have with the one we have “inherited”.
- Unsupported PHP 5.6
- Unsupported Laravel 4.2
- jQuery snippets used all over many different HTML files produced by Blade - Laravel’s templating engine.
That would be for the beginning. This system was supposed to be fed by an API and it partially was, however, during the most active development phase over 20 tables appeared in its own database, in most cases very “loosely related”, if at all. I believe that happened to speed up delivering short term functionality, but it actually illustrates the scale of the problem.
Who doesn't love pasta?
Several months ago I joined a team formed exactly for the purpose of “fixing the situation”. The situation where a system responsible for the company’s sophisticated licensing policy - and thus impacting its hundreds of thousands of users is extremely difficult to maintain. A system where a developer spends an enormous amount of time to develop a simple feature and one knows it’s still far from releasing it to its users. Almost each and every area required improvement: security, upgrading old packages and libraries to newer versions, development, release process, testing and maintenance. I must admit the quality of the single's class or method code wasn’t bad, but the overall picture looked ugly.
The business was aware of the problem and formed a team with only very experienced team members in it. BTW, it was the first project in my life with only senior developers around me.
After weeks of discussions, we’ve come up with a high-level plan and managed to convince the business too.
We decided to decompose the monolithic beast into micro-apps and/or micro-services. If you want to justify that decision the following is our thinking process:
- The legacy system mustn’t be turned off and replaced.
- The improvements have to fit in the agile methodology used all over the company in all projects and teams.
- We need to deliver any value as soon as possible.
- We want to change the stack as per the company’s manifesto to use React as a frontend technology.
- Applying asynchronous solutions wherever possible.
- The opportunity to build dedicated teams in future that could focus on a reduced complexity and limited responsibility chunk.
- Releasing a small feature should not require hours of automated tests and days of manual testing.
We decided to decompose the legacy system by doing a split based on functionality (sort of contexts) and we formed the following groups of future services:
- Micro-apps (frontend + api, with persistent storage)
- Micro-services (api or worker or both, with persistent storage)
- Proxies (frontend + api, no persistent storage)
Let Me In
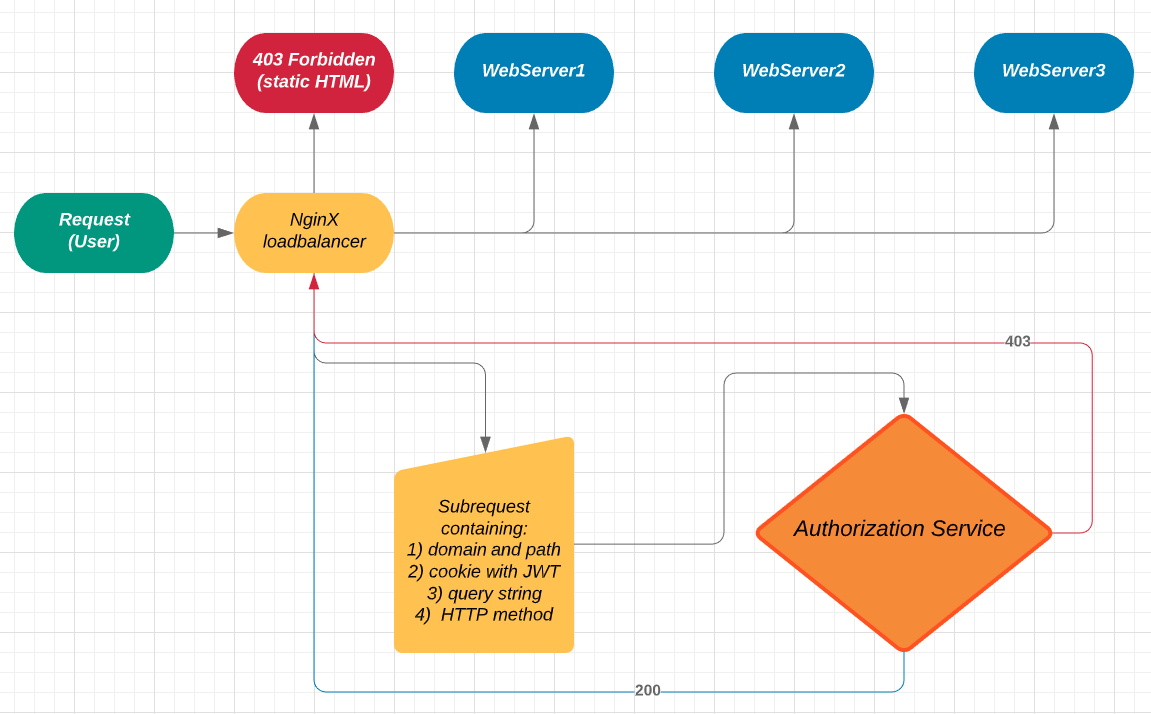
By doing this we’ve immediately discovered a problem (or a challenge) that requires addressing first. In a monolithic system you let the user sign in and usually set a session. Then every next call to the server is authorized for as long as the session is active. But what if you have more apps that sort of live on their own? There are few ways of how this is usually solved. We’ve decided to move the authorization mechanism from the webserver to the network level. That means our webservers themselves are “unconscious”, but any traffic reaching them is passed to the authorization service bound with the load balancer. The authorization service is responsible for checking if that request is permitted. It takes the original request as a “subrequest” and acts as a logic gate responding with 200 or 403 to the load balancer. What are the pros and cons of our approach? The first is obvious - you don’t need to duplicate any logic related with authorizing requests on your webservers. The cons (debatable though) are for example:
- The authorization service requires some understanding of the system (paths, methods, etc.) to “decide” if access is permitted.
- The authorization service must be extremely reliable and fast. Remember every single request, including assets ones, is passed to it and the time it requires to authorize must be added to the total time to process any single request.
To respond to A. we’ve created another micro-service called “Roles and permissions”. It has its own dedicated storage and is responsible for all the data about who can do what.
Addressing B. was a bit more challenging, but in the end our authorization service is both extremely reliable and fast and still PHP based. To be precise it’s a Swoole server. Have a read about this technology, you won’t regret it. Worth mentioning is that our Swoole server reads an optimized set of rules and permissions (A.) while starting and keeps them in memory.
A simplified diagram of what we tried to achieve with the authorization layer could look the following:
Work, work...
As previously mentioned, we wanted to implement as much functionality as possible in the asynchronous fashion. The first decomposed functionality that records all events related to the user, products, licenses was a great chance to do it that way. The monolithic system switched from saving an event data into a database to pushing a message to the message bus. Then a worker picks that message up and a processed message is saved in its own storage. More than that - the new microservice is also exposing an API to enable searching for events or retrieving a single event information. This is the group no. 2) mentioned above. We have a few more microservices now which follow this scenario and I think it’s worth mentioning why and how we do the “workers”.
The message bus is another part of the system that has to be reliable. We chose RabbitMQ, an industry standard technology, to power our queues. Even when we internally discuss failure scenarios or try to identify single failure points, we do not consider the unavailability of a message bus. On the other hand, it’s more likely a worker could fail while processing a message. Especially when the result is written to the database or when a request to internal or external API is sent. To avoid a problem of missing data we introduced a way to handle failures during message processing. We decided to use a retry strategy setting an incremental “x-delay” number in minutes from an exponential sequence. If messages are not processed correctly within a certain period, they are moved to a failure queue and wait there for a decision.
RabbitMQ is a very powerful technology. It supports many useful features to mention different exchange types. It may also help you handle message versioning, if your message structure gets changed upon the project’s life.
KISS!
But what if we cannot extract a bit of functionality and delegate it to a separate server? What if we have a complex page where it wouldn’t make sense to extract part of its functionality? We did decompose a few complex pages from the monolithic system and they became either 1) or 3) depending on having its own storage. Once we addressed the authorization issue the only problem left is to match certain URI paths and forward them to another webserver. In our case the first page delegated was a “Search”. Because all the data the user could search for are stored in an API this micro app is a sort of proxy. React frontend makes requests to the backend service which validates it and passes it to the API. We couldn’t call this API from React directly because we mustn’t reveal its secrets to the end user.
Micro summary
We are very happy with the process at the moment. Every few sprints we pull another bit from the monolithic system and turn it into a separate service. With its own codebase, tests, release process and, one day, with its dedicated team. Usually we not only “rewrite” it to match newer environment and dependencies but also add functionality awaited by the business for a long time. With having a reduced complexity and functionality, the project is far easier and far more efficient.
